Datenbeschaffung, -bereinigung und -speicherung
Datenbeschaffung
Vorlesungsverzeichnisse
Wie beschrieben liegen die Veranstaltungsdaten an den meisten Hochschulen online in den Vorlesungsverzeichnissen vor. Doch wie gelangt man an diese Daten und überführt sie in eine für die Analyse geeignete Datenstruktur? Grundsätzlich stehen hierfür zwei praktikable Möglichkeiten zur Verfügung: (1.) Man erhält von den Hochschulen einen entsprechenden Datenexport der interessierenden Felder/einen Schnittstellenzugang (API) aus/zu ihrer Veranstaltungsdatenbank oder (2.) man extrahiert aus den Websites die gewünschten Informationen maschinell (Web Scraping).
Datenbankauszüge Vorlesungsverzeichnisse/API: Zum Teil geben und gaben die Hochschulen dem Stifterverband auf die Frage, ob die Vorlesungsverzeichnisse gescraped werden dürfen, entsprechende Datenbankauszüge direkt. Die Übermittlung erfolgte und erfolgt dabei je Hochschule in unterschiedlichen Formaten und Austauschwegen. Der Vorteil dieser Variante: Es muss kein Scraping-Skript geschrieben werden und die Hochschulen behalten die volle Kontrolle über die Informationen, die sie zugänglich machen. Die Nachteile: Erfahrungsgemäß ist die Zuständigkeit innerhalb der Hochschule für derartige Forschungsanfragen wie HEX nicht immer leicht zu klären und auch die Bedürfnisse an die Spezifikationen des Datenbankauszuges müssen ausreichend kommuniziert werden. Zusätzlich ist die Übermittlung jedes Semester nötig und Ressourcen in der Hochschulverwaltung und -IT werden somit gebunden. Obgleich im ersten Moment widersprüchlich wirkend ist das Datenmanagement bei Hochschuldatenbankauszügen oftmals komplexer als beim Beziehen der Daten mittels Scraping.
Scraping Vorlesungsverzeichnisse: Beim Web Scraping wird der Quellcode einer Internetseite heruntergeladen und anhand der Dokumentenstruktur die interessierenden Abschnitte extrahiert und in eine zur Datenanalyse geeignete Datenstruktur transferiert. Der Stifterverband schreibt hierfür vorlesungsverzeichnisspezifische Auslese-Skripte in der Programmiersprache R (insbesondere unter Nutzung der Packages rvest und bei dynamischen Websites RSelenium). Zusätzlich werden für das Scraping auch Skripte in Python eingesetzt, insbesondere unter Verwendung der Bibliotheken Beautiful Soup und Selenium, um flexibel auf verschiedene technische Anforderungen der Vorlesungsverzeichnisse reagieren zu können. Die so erstellten Datensätze werden anschließend gespeichert. Web Scraping ist gerade im Forschungskontext in der Regel als legal einzustufen, dennoch gibt es Ausnahmen und Regeln. So ist zum Beispiel zu prüfen, ob eine sogenannte robots.txt-Datei vorliegt. Hierbei handelt es sich um Textdateien, in denen die Website aufzeigt, ob und wenn ja welche sogenannten Crawler, Scraper und Bots zur Erfassung von Webinhalten die Seite bzw. Unterseiten durchforsten dürfen. Verbietet eine robots.txt das Scraping, so ist eine Erlaubnis einzuholen.
Zusätzliche Daten
Neben den Daten aus den Vorlesungsverzeichnissen werden auch potenziell relevante Kontext- oder Zusatzinformationen sowie Analyseergebnisse in die HEX Datenbank gespeichert und in der Einordnung der Ergebnisse verwendet.
Kontext und Zusatzinformationen: Die allgemeinen Daten der Hochschulstatistik (Grundgesamtheit der Hochschulen, Studierenden- und Prüfungsstatistiken, Hochschulfinanzstatistiken und Statistiken zum wissenschaftlichen und künstlerischen Personal) werden vom Statistischen Bundesamt (Destatis) bezogen. Der Datenbezug erfolgt teilweise über das Auslesen der (alten) Fachserien, über GENESIS und/oder als Bestellung. Darüber hinaus werden noch weitere Kontextdaten, zum Beispiel zu den einzelnen Hochschulstrukturen, zu Förderprogrammen oder Studiengängen, gescraped und mit den Daten kombiniert. Institute und Lehrstühle werden soweit möglich mit der GERIT-Datenbank für eine Zuordnung abgeglichen.
Analyseergebnisse: Gerade im Bereich des maschinellen Lernens (siehe auch Abschnitt maschinelles Lernen) erfordern einige Analysen längere Berechnungszeiten. Um die Analysen nicht immer wieder durchführen zu müssen, werden bestimmte Analyseergebnisse, beispielsweise die Future Skill Klassifikation, direkt mit den Daten gespeichert.
Datenbereinigung und -management
Die erhaltenen/extrahierten Daten sind oftmals noch nicht analysierbar. Fehlerhaft ausgelesene Datensätze, Dubletten, HTML-Artefakte und dergleichen müssen aus dem Datensatz entfernt werden. Zudem muss zumindest stichprobenartig ein Abgleich mit der ursprünglichen Datenquelle erfolgen. Oftmals müssen Hochschulstruktur und Veranstaltungsdetails noch durch Datenmanagementoperationen zusammengebracht und wenn möglich vereinheitlicht werden. Teils ist auch eine nach verschiedenen Regeln erfolgende Zuordnung (zum Beispiel zu Fachbereichen) und eine Vereinheitlichung von Strukturen (zum Beispiel Namensunterschiede in konzeptionell gleichen Fachbereichen und Instituten) nötig. Auch müssen die Datensätze zu den einzelnen Semestern und/oder Hochschulen korrekt miteinander homogenisiert und zusammengeführt werden. Bei personenbezogenen Daten (Name der Dozierenden) muss eine entsprechende Löschung oder Anonymisierung erfolgen.
Kurssprache: In einigen Fällen war die Unterrichtssprache der Kurse nicht explizit im Vorlesungsverzeichnis angegeben Für die betroffenen Hochschulen haben wir versucht, diese Variable zu ergänzen, indem wir die Sprache des Kurstitels und der Kursbeschreibung analysiert haben. In den Fällen, in denen die Kurssprache nicht verfügbar ist, prüfen wir, ob die Kursbeschreibung ausgefüllt ist, und ermitteln die Sprache anhand dieses Textes (dies ist im Allgemeinen ein längerer Text, was zu einer genaueren Spracherkennung führt). Wenn die Kursbeschreibung nicht ausgefüllt ist, wenden wir uns dem Kurstitel zu - da diese im Allgemeinen recht kurz sind, verwenden wir zwei verschiedene Spracherkennungspakete und identifizieren Kurse nur dann als Englisch, wenn beide Methoden übereinstimmen (dies führt zu einer konservativen Schätzung).
Datenspeicherung
Die Daten in HEX werden in einer PostgreSQL-Datenbank gespeichert. Diese umfasst vier Schemata.
In hex (ER-Farbe grau) sind alle Tabellen, deren Informationen direkt aus den Vorlesungsverzeichnissen abgerufen wurden. Beispiele sind Veranstaltungen, Lehrpersonen und Institut.
In kontext (grün) sind alle Tabellen, auf deren ID direkt aus dem hex-Schema (alle Informationen aus den Vorlesungsverzeichnissen) zugegriffen wird. Beispiele sind Hochschule, Sprache, oder Fachgruppe.
In zusatz (weiß) sind weitere Informationen gespeichert, die generell oder zu den kontext-Daten nützlich sind. Beispiele sind Future Skills, Studierendenzahlen und Hochschulbudgets.
In analysen (gelb) sind alle Tabellen, auf deren ID direkt aus dem hex-Schema (alle Informatione aus den Vorlesungsverzeichnissen) zugegriffen wird. Beispiele sind die Future Skill Klassifikation oder für Analysen erstellte Views zur erleichterten Analyse
Die Datenbankstruktur lässt sich auch aus dem Entity Relationship Diagramm (ER-Diagramm) darstellen. Die Hintergrundfarbe der Tabellennamen zeigt das dazugehörige Schema an:
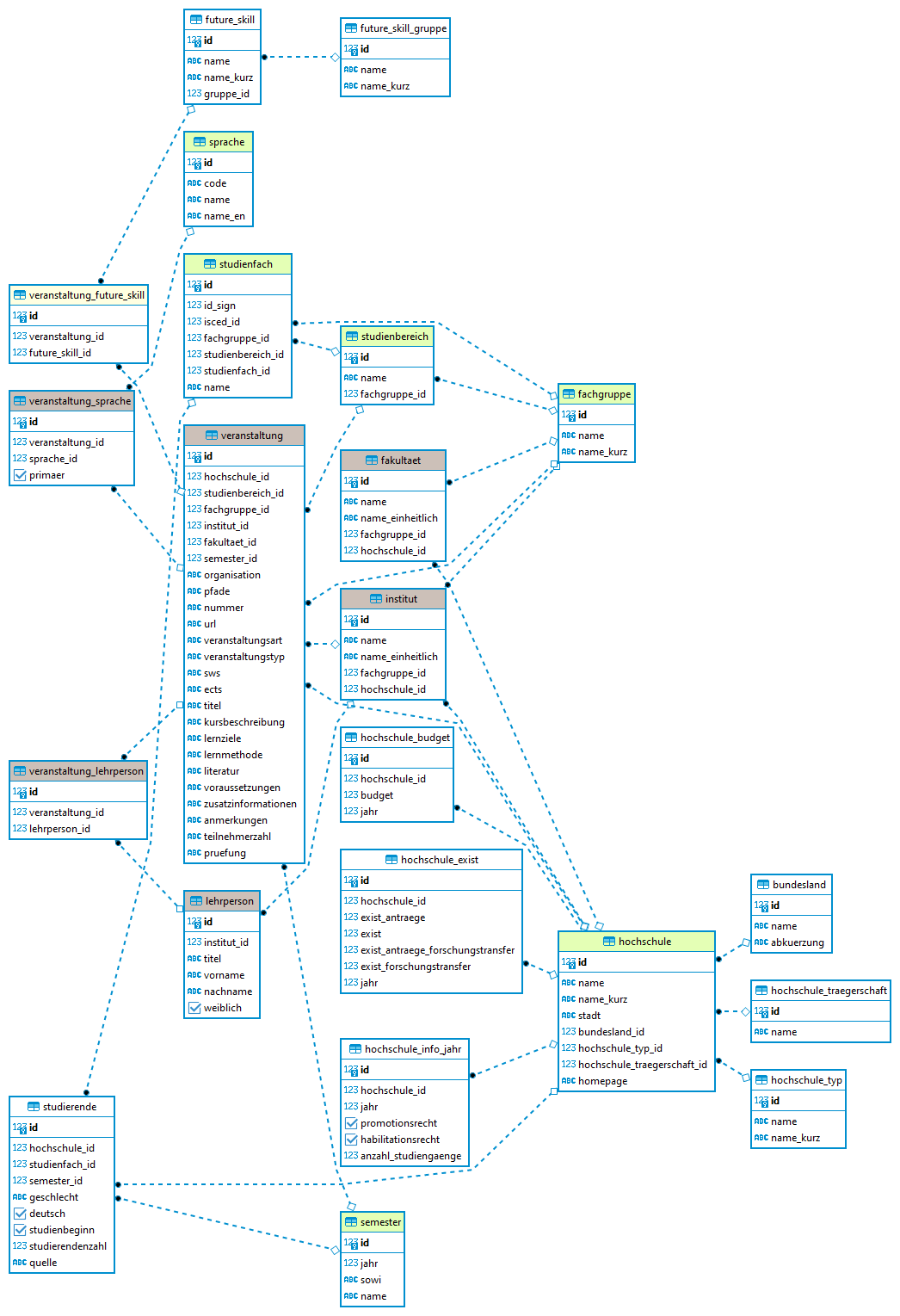
Für die HEX-Applikation (siehe Abschnitt Infrastruktur und angrenzende Produkte) wird die PostgresSQL in eine DuckDB umgeformt, um mit der Applikation ohne Serverzugang übertragbar zu sein.